
Summary
- Introduction
- What is AskMyPdf?
- Architecture and Technologies
- Technical Challenges and Solutions
- Demo
- Opportunities and Applications
- Glossary of Terms
- Conclusion
Introduction
Most critical information in companies, universities, and public agencies is still stored in static PDFs—difficult to search, slow to navigate, and almost impossible to interact with. With this in mind, I developed AskMyPdf, an open source application that transforms PDF documents into queryable interfaces using generative AI.
The system integrates open source language models (LLMs), vector search with embeddings, and a Python architecture with FastAPI. It adopts the RAG (Retrieval-Augmented Generation) paradigm, where relevant excerpts are located in the documents and used as context to generate contextualized and reliable answers.
What is AskMyPdf?
The AskMyPdf allows anyone to upload PDFs, process and index the content using vector embeddings, and then interact with these documents through natural language questions. Answers are generated based exclusively on the content of the provided files.
This type of solution is especially useful in scenarios where the volume of information makes a full reading unfeasible. It can be applied by companies with large internal documentation, legal departments, teachers, researchers, students, and professionals dealing with extensive materials.
Architecture and Technologies
The project was built in Python, focusing on modularity, performance, and ease of integration.
The API is provided via FastAPI, and the system core uses LangChain to orchestrate loaders, chunking, vector indexing, and the question-and-answer logic. Embeddings are generated and stored with FAISS, while text extraction from PDFs is done with PyMuPDF. To facilitate deployment, the system is containerized with Docker and configured via environment variables (.env).
The language model can run locally (via LM Studio, Ollama, etc.) or through external APIs like OpenAI, allowing flexibility according to privacy or performance constraints.
Architecture Diagram
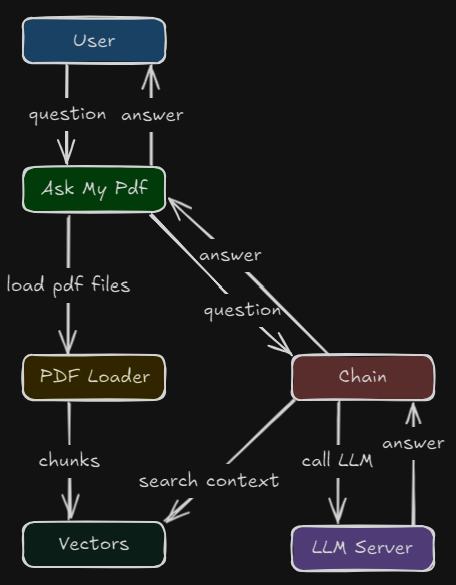
Diagram Block Legend
-
User: Interacts with the API or playground, sending questions and receiving contextualized answers.
-
AskMyPdf: Main component, responsible for coordinating the flow between user input, PDF loading, and answer generation.
-
PDF Loader: Reads PDF files, extracts text, and splits the content into chunks.
-
Vectors: Stores the embeddings of the chunks, enabling fast semantic similarity searches.
-
Chain: Chains the RAG logic—searches for the most relevant excerpts, builds the context, and triggers the LLM.
-
LLM Server: Runs the language model and generates the answer based on the received context.
Operation Flow
The entire process can be divided into five main steps:
-
Ingestion: The user adds PDF files to a monitored directory or sends them via API. The system loads the content and splits it into small chunks for processing.
-
Indexing: Each chunk is transformed into a semantic vector and stored with FAISS to enable similarity searches.
-
Interaction: When a question is sent, AskMyPdf forwards the request to the orchestration module.
-
Contextualization and Answer: The system searches for the most relevant excerpts in the vector index, builds the context, and triggers the language model to generate the answer.
-
Delivery: The generated answer is returned to the user via API, playground, or another connected front-end.
Technical Challenges and Solutions
During development, I faced some critical points that required special attention:
-
The rapid evolution of libraries (such as LangChain, FastAPI, and Pydantic) required strict version control to ensure stability and compatibility.
-
To ensure answer quality, I implemented a custom embeddings pipeline combined with FAISS, enabling more precise semantic searches.
-
The architecture was designed to work with both local LLMs and external APIs, ensuring flexibility for different levels of privacy and performance.
-
To facilitate tool validation and user experience, I incorporated an interactive playground with LangServe.
Demo
Below, I configured a local LLM server using LM Studio:
Demo of AskMyPdf answering questions from PDFs.
You can find the full project on GitHub
Opportunities and Applications
AskMyPdf can be easily adapted for various scenarios:
-
Companies: Querying contracts, internal policies, technical documents, and manuals.
-
Legal: Fast and contextualized search in extensive cases or legislation.
-
Education: Active reading of didactic materials and scientific articles.
-
Research: Dynamic interaction with papers and technical documents.
Additionally, the project demonstrates skills applicable to professional contexts:
-
AI-focused software engineering
-
Orchestration of LLMs and NLP pipelines
-
API and microservices integration
-
Containerization and modern deployment practices
Glossary of Terms
- FAISS: Library developed by Facebook for efficient vector search, used to quickly find similar information in large volumes of data.
- LLM (Large Language Model): Large-scale language model trained on vast amounts of text, capable of understanding and generating natural language (e.g., GPT, Llama).
- LangChain: Python library that facilitates the integration of language models, question-and-answer flows, and database search.
- NLP (Natural Language Processing): Area of artificial intelligence dedicated to processing, understanding, and generating human language by computers.
- Embeddings: Numerical representations of texts or words, allowing semantic similarity comparison between different text excerpts.
- RAG (Retrieval-Augmented Generation): Technique that combines searching for relevant information in databases with answer generation by language models.
- FastAPI: Modern and fast web framework for building APIs in Python.
- PyMuPDF: Python library for text extraction and manipulation of PDF files.
- Docker: Platform for creating, distributing, and running applications in containers, facilitating deployment and portability.
- Playground/LangServe: Interactive interface for testing and demonstrating the system’s operation.
Conclusion
AskMyPdf demonstrates in practice how to apply LLMs, vector embeddings, and a lean Python architecture to make PDF documents searchable through natural language. By combining generative AI with semantic search, the solution enables fast and contextualized access to information that would traditionally require manual reading.
With support for both local and remote models, the system adapts to different privacy and performance requirements. It is applicable in contexts such as internal support, document analysis, education, and technical research.
If this content brought you insights or inspiration, share it with your network. Adopting and evolving solutions with open source LLMs can be a strategic differentiator—for both developers and users.
